Кевин А. Батлер, Дэн Дин, компания Esri
Analysis Patterns for Multidimensional Scientific Data
 Хранение данных в нескольких измерениях позволяет исследователям и ГИС-аналитикам собирать и анализировать материалы наблюдений, полученные под земной поверхностью, в земной атмосфере и океанах. Для работы с такими данными имеется несколько методов, рассматриваемых в данной статье. Для автоматизации соответствующих рабочих процессов и продвинутого анализа многомерных данных применяются широкие возможности платформы ArcGIS и входящие в ее состав инструменты геообработки и средства программирования.
Хранение данных в нескольких измерениях позволяет исследователям и ГИС-аналитикам собирать и анализировать материалы наблюдений, полученные под земной поверхностью, в земной атмосфере и океанах. Для работы с такими данными имеется несколько методов, рассматриваемых в данной статье. Для автоматизации соответствующих рабочих процессов и продвинутого анализа многомерных данных применяются широкие возможности платформы ArcGIS и входящие в ее состав инструменты геообработки и средства программирования.
Рабочие процессы ГИС исторически были рассчитаны на двумерные данные. Однако в дополнение к знакомым пространственным измерениям в координатах x/y собираемые данные могут иметь одно или более дополнительных измерений.
Пространство с тремя такими измерениями можно представить в виде куба с соответствующими осями (рис. 1). Данные могут быть привязаны к регулярной сетке (как растр) или представлять собой точки (с одной точкой – центроидом каждой ячейки массива). В случае океанологических данных третье измерение может, например, содержать данные о глубине (x, y, z), а для атмосферных данных – об уровне давления водяного пара в атмосфере (x, y, p). Третье измерение также используется для хранения времени (x, y, t).
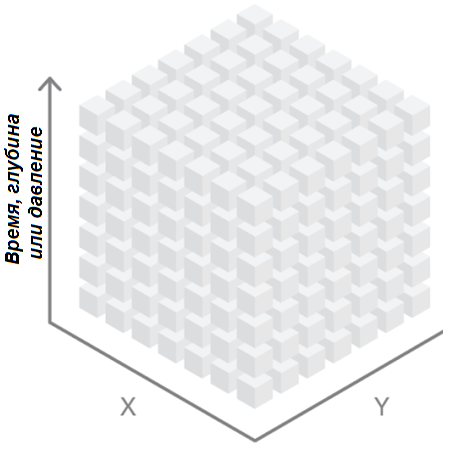 Рис. 1. Многомерные данные с тремя измерениями могут быть визуализированы в виде куба.
Рис. 1. Многомерные данные с тремя измерениями могут быть визуализированы в виде куба.
Четырехмерные наборы данных могут содержать пространственные данные (измерения x и y) на разных глубинах или высотах (z) и в разное время (t), что в итоге дает набор данных x, y, z, t (рис. 2).
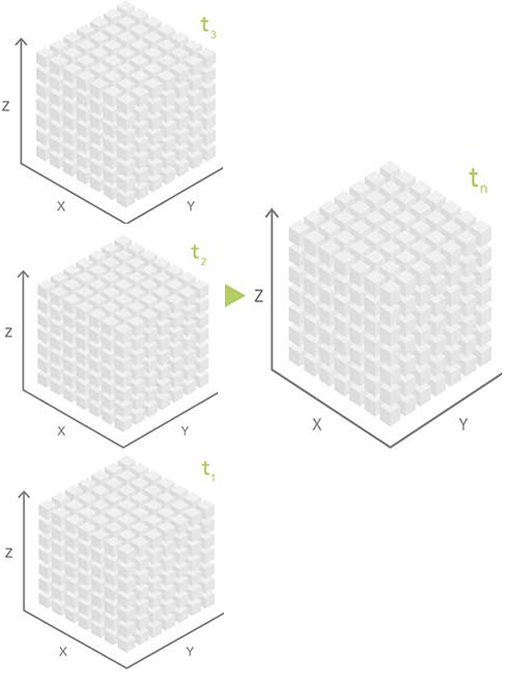 Рис. 2. Четырехмерные наборы данных хранят пространственные данные (измерения x и y) на разных глубинах или высотах (z) в разное время (t), что дает набор данных x, y, z, t.
Рис. 2. Четырехмерные наборы данных хранят пространственные данные (измерения x и y) на разных глубинах или высотах (z) в разное время (t), что дает набор данных x, y, z, t.
В отличие от обычных данных реляционных баз данных или ГИС-информации, форматы научных данных оптимизированы для хранения многомерных данных и соответствующих им метаданных. Для эффективного хранения таких данных научное сообщество разработало специализированные форматы файлов, такие как Network Common Data Form (netCDF), Hierarchical Data Format (HDF) и Gridded Binary (GRIB).
Поддержка формата netCDF появилась в ArcGIS, начиная с версии 9.2, – в наборе инструментов Многомерные данные (Multidimensional toolbox). Эти инструменты поддерживают растровые, векторные (точечные) и табличные данные. Поддержка растровых данных, хранящихся в форматах HDF и GRIB, была введена в наборах данных мозаики – в версии 10.3. Поддержка этих форматов в ArcGIS позволяет интегрировать многомерные научные данные в рабочие процессы ГИС и использовать ArcGIS в качестве платформы для обработки и анализа таких данных.
Способы анализа
По словам Мартина Фаулера (Martin Fowler), паттерны анализа – это способы задокументировать «идею, которая оказалось полезной на практике в одном случае и, вероятно, будет полезна и в других». Фаулер, британский разработчик программного обеспечения, специализирующийся на объектно-ориентированном анализе и проектировании, UML, паттернах и методах гибкой разработки программного обеспечения, представил эту концепцию в 1997 году для обеспечения высокого уровня абстракции аналитического рабочего процесса. «Срез за срезом», от англ. Slice by slice (в пределах одного файла либо в нескольких отдельных файлах), «местоположение за местоположением» (location by location), «агрегирование» (aggregation) и «кастомизация» (custom) – вот четыре основных паттерна, использующиеся для анализа многомерных данных (рис. 3, 4). Первые три из них могут быть выполнены напрямую с использованием инструментов геообработки и приложения ModelBuilder в ArcGIS. Последний подход также реально осуществить, но он является пользовательским и требует некоторых навыков программирования.
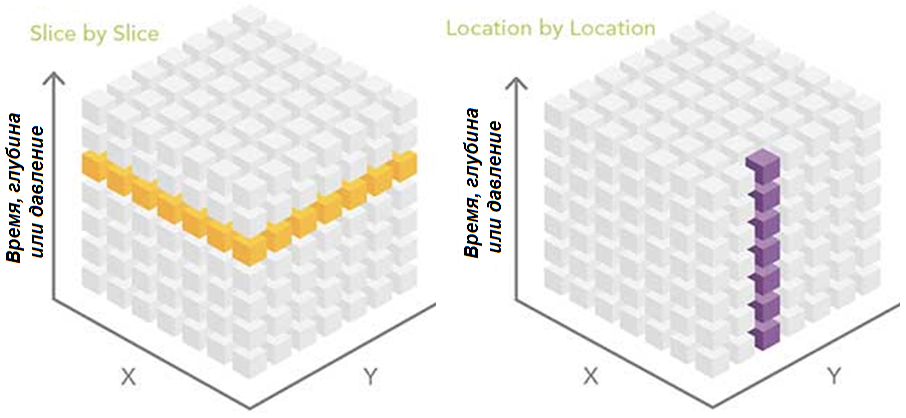 Рис. 3. Способы анализа «срез за срезом» и «местоположение за местоположением» представляют собой абстракцию высокого уровня различных подходов к рабочим процессам анализа.
Рис. 3. Способы анализа «срез за срезом» и «местоположение за местоположением» представляют собой абстракцию высокого уровня различных подходов к рабочим процессам анализа.
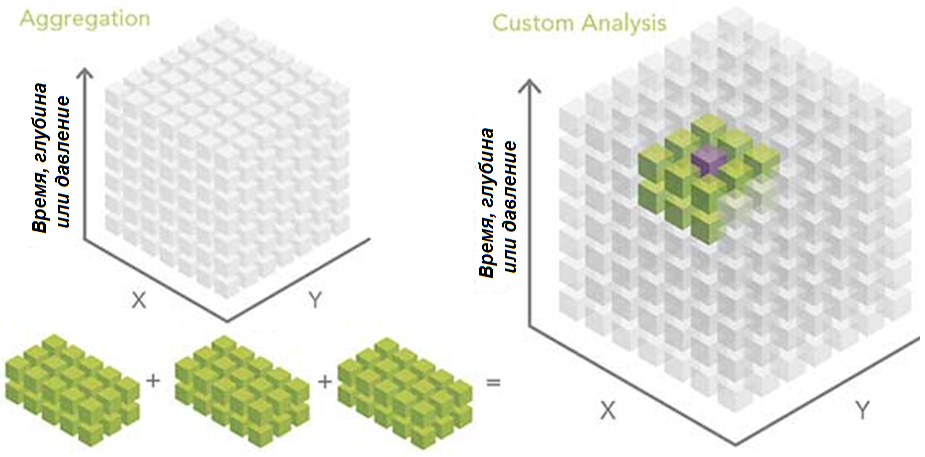 Рис. 4. Агрегирование и кастомизация – два дополнительных способа анализа многомерных данных.
Рис. 4. Агрегирование и кастомизация – два дополнительных способа анализа многомерных данных.
Срез за срезом
Способ анализа «срез за срезом» работает с данными в одном или нескольких файлах. Обычный процесс работы с многомерными данными обрабатывает один срез набора данных за раз. Этот срез может соответствовать одному значению глубины, высоты либо одному периоду времени. Многомерный набор данных можно сравнить с колодой игральных карт. Каждая карта в колоде представляет собой двумерный срез, и ее можно проанализировать с помощью ряда инструментов геообработки, доступных в ArcGIS. Одним из недостатков такого подхода к анализу является то, что он не учитывает информацию о других глубинах, высотах или временных периодах.
Чтобы начать анализ «срез за срезом», запустите один из инструментов создания NetCDF из набора инструментов Многомерные данные. Этот набор содержит инструменты геообработки, которые создают растровый слой, векторный слой или представление таблицы netCDF. Каждый из этих инструментов имеет необязательный параметр, который позволяет выбрать измерение (срез), которое будет использоваться для создания слоя netCDF. Значение измерения может быть выражено численно (мм / дд / гггг) или индексом.
Значению первого измерения в файле netCDF присваивается индекс, равный нулю. Индекс измерения увеличивается на единицу для каждого следующего среза. Например, файл netCDF, содержащий пять временных срезов, может содержать значения измерений 2001, 2002, 2003, 2004 и 2005 гг. На те же самые временные срезы можно ссылаться, используя индексы измерений 0, 1, 2, 3 и 4.
При итерации по срезам файла netCDF чаще всего оказывается удобнее работать с индексами измерений, особенно при использовании итератора ModelBuilder. Итератор начинается с нуля (это первый срез файла netCDF) и проходит по модели до тех пор, пока не будет обработан последний срез файла netCDF. Пользователь должен указать последнее значение итератора.
Хотя файлы netCDF предназначены для хранения нескольких срезов данных, некоторые ограничения обработки, например, ограничения размера файла, циклы быстрого обновления или необходимость быстрого перемещения файлов через Интернет, приводят к невозможности создания больших файлов netCDF с большим числом срезов. Это часто случается, когда файлы netCDF должны проходить через брандмауэры безопасности или являются выходными данными моделей, которые постоянно генерируют новые временные срезы.
Чтобы обойти эти ограничения, поставщики данных могут создавать файл netCDF для каждого среза. В этом случае пользователь должен будет по очереди анализировать эти файлы либо объединить их в новый файл. Рабочий процесс поочередного анализа файлов очень похож на метод «срез за срезом», применяемый для одного файла.
Местоположение за местоположением
Многомерные данные, основанные на растре, можно рассматривать как серию регулярных сеток, накладываемых друг на друга. Каждый срез стека содержит различную глубину, давление или время. В некоторых видах анализа аналитик должен обрабатывать каждую ячейку растра (местоположение) по глубине или по времени. Концептуально это напоминает «протыкание» куба в каждой его ячейке, как бы нанизывание ее на шампур, и выполнение определенной операции со всеми ячейками, через которые мы пройдем. Этот рабочий процесс может быть выполнен путем укладки срезов многомерных данных в многоканальный растр. Некоторые инструменты геообработки в ArcGIS, такие как «Статистика по ячейкам» (Cell Statistics) и «Статистика набора каналов» (Band Collection Statistics), сами понимают, как обрабатывать многоканальные растры.
Агрегирование точечных и табличных данных в пространстве и/или по времени
Многомерный набор данных мозаики – оптимальное решение для пространственного и временного агрегирования многомерных растровых данных. Однако для объединения векторных и табличных данных необходимы рабочие процессы, основанные на геообработке. Размер файла, циклы быстрого обновления и другие ограничения могут привести к тому, что научные данные будут организованы таким образом, что данные за каждый год сохраняются в отдельном файле. Обычный подход заключается в объединении данных в один файл и последующем анализе полученных данных. Примером может быть получение среднемесячных значений за несколько лет.
Пользовательский анализ посредством Python
Инструменты геообработки, такие как Создать растровый слой NetCDF (Make NetCDF Raster Layer), Создать слой объектов NetCDF (Feature Layer) и Создать представление таблицы NetCDF (Table View), наряду с мощными возможностями многомерного набора данных мозаики, обеспечивают широкий спектр рабочих процессов, предназначенных для анализа многомерных данных. В некоторых случаях, однако, применение подходов «срез за срезом» и «местоположение за местоположением» может оказаться недостаточным. К счастью, начиная с версии ArcGIS 10.3, в качестве составной части платформы ArcGIS начала поставляться новая библиотека Python netCDF4.
Эта библиотека позволяет легко выполнять проверку, считывание, объединение и запись файлов netCDF. Данные считываются модулем netCDF4 и сохраняются в массив numPy с его мощными возможностями секционирования массивов. Данные можно разрезать, указывая индексы. Например, у переменной tmin три измерения: год, широта и долгота. Задав индекс (или диапазон индексов), вы вырежете из трехмерного куба данных кубик меньших размеров.
Наряду с возможностями Python netCDF4, для быстрого создания моделей автоматизированного выполнения многих рабочих процессов на основе доступных инструментов геообработки целесообразно использовать приложение ModelBuilder. Некоторые примеры применения этих ресурсов и возможностей для выполнения анализа многомерных наборов данных приведены на рисунках 5-9.
 Рис. 5. ModelBuilder может применяться для выполнения анализа данных «срез за срезом» в одном файле. Каждый раз, когда модель циклически повторяется (выполняется итератор), будет подставлено значение, сгенерированное итератором. Обратите внимание, что такая же подстановка встроенных переменных используется, чтобы для выходных данных инструмента «Изменить разрешение» использовались уникальные имена.
Рис. 5. ModelBuilder может применяться для выполнения анализа данных «срез за срезом» в одном файле. Каждый раз, когда модель циклически повторяется (выполняется итератор), будет подставлено значение, сгенерированное итератором. Обратите внимание, что такая же подстановка встроенных переменных используется, чтобы для выходных данных инструмента «Изменить разрешение» использовались уникальные имена.
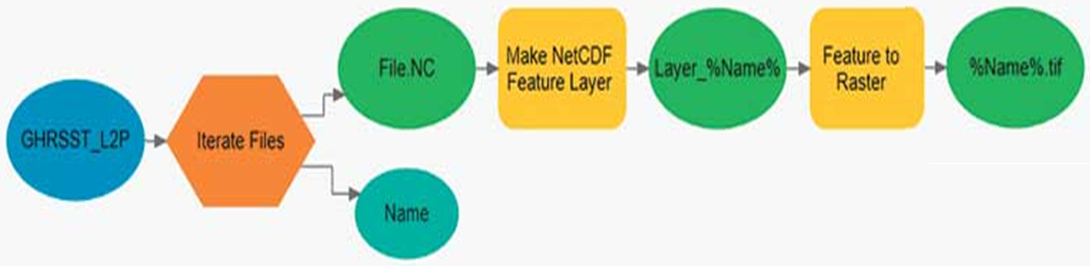 Рис. 6. В этом рабочем процессе несколько файлов netCDF содержатся в одном файловом каталоге, а вместо итератора цикла FOR используется итератор файлов. Итератор файлов сканирует указанное местоположение и создает список файлов для обработки. В результате подстановки встроенных переменных имя файла (%Name%) передается в инструмент «Создать слой объектов netCDF», а полученный векторный слой netCDF – в инструмент «Плотность ядер» для интерполяции растровой поверхности.
Рис. 6. В этом рабочем процессе несколько файлов netCDF содержатся в одном файловом каталоге, а вместо итератора цикла FOR используется итератор файлов. Итератор файлов сканирует указанное местоположение и создает список файлов для обработки. В результате подстановки встроенных переменных имя файла (%Name%) передается в инструмент «Создать слой объектов netCDF», а полученный векторный слой netCDF – в инструмент «Плотность ядер» для интерполяции растровой поверхности.
 Рис. 7. Данный рабочий процесс использует параметр «Измерение канала» инструмента «Создать растровый слой NetCDF» для преобразования измерений netCDF, в частности глубин или временных диапазонов, в каналы выходного растра.
Рис. 7. Данный рабочий процесс использует параметр «Измерение канала» инструмента «Создать растровый слой NetCDF» для преобразования измерений netCDF, в частности глубин или временных диапазонов, в каналы выходного растра.
 Рис. 8. В этом примере агрегируются данные о температуре путем выполнения итерации по списку файлов, содержащих данные о суточном количестве выпавших осадков за четыре года. Таблица, создаваемая для каждого года с помощью инструмента Создать представление таблицы NetCDF, добавляется к целевому файлу, который по завершении процесса передается в различные рабочие процессы анализа.
Рис. 8. В этом примере агрегируются данные о температуре путем выполнения итерации по списку файлов, содержащих данные о суточном количестве выпавших осадков за четыре года. Таблица, создаваемая для каждого года с помощью инструмента Создать представление таблицы NetCDF, добавляется к целевому файлу, который по завершении процесса передается в различные рабочие процессы анализа.
 Рис. 9. Этот фрагмент кода на Python извлекает данные за первые пять лет для переменной tmin и печатает сводную статистику. Полученные массивы numPy могут быть переданы любому количеству модулей Python для пользовательского анализа.
Рис. 9. Этот фрагмент кода на Python извлекает данные за первые пять лет для переменной tmin и печатает сводную статистику. Полученные массивы numPy могут быть переданы любому количеству модулей Python для пользовательского анализа.
Заключение
Платформа ArcGIS предоставляет вам множество способов анализа многомерных научных данных, позволяя смоделировать и, в результате такого моделирования, лучше понимать происходящие на Земле процессы. Esri постоянно разрабатывает и совершенствует инструменты и рабочие процессы, предназначенные для сбора, управления, анализа, визуализации и обмена многомерными данными.
Об авторах
Кевин А. Батлер – разработчик группы пространственной статистики Esri и участник группы Esri «Виртуальная наука». Он имеет докторскую степень по географии Кентского госуниверситета.
Дэн Дин – разработчик группы обработки растров Esri. Она имеет докторскую степень по географии Университета Айовы.